Understanding session-based authentication
Note: This is a continuation of my articles on how authentication works…If you haven’t read my previous article on Decoding the JSON Web Token (JWT), I recommend doing so before reading this follow-up article.
Let’s understand the concept of session-based authentication by answering a few common questions.
- What are session IDs?
Session IDs are nothing but a unique ID created for each user once they log in to the system. Session ID acts as a key which is used to map the user against their session.
Example:
users_sessions
+----+---------+--------------+---------------------+
| id | user_id | session_key | timestamp |
+----+---------+--------------+---------------------+
| 1 | 1234 | abcdef123456 | 2021-10-01 12:00:00 |
| 2 | 5678 | qwerty098765 | 2021-10-02 14:30:00 |
| 3 | 9012 | asdfgh987654 | 2021-10-04 09:15:00 |
+----+---------+--------------+---------------------+- When are session IDs generated?
- When a user successfully logs into an application (please refer to my previous article on how basic authentication happens), a unique temporary identifier is generated which we call session ID.
- This session ID is unique and is tied to the user’s account by the application.
- Where is this session data stored on the server?
On the server, the session ID is typically stored in a server-side session storage, which can be implemented using a variety of techniques such as a database table, a cache, or a server memory.
In a typical implementation, the session ID and associated data are stored in a table in a database or a cache such as Redis or Memcache.
- How does the client store this data?
On the client (browser), this is typically stored as an HTTP-based cookie. HTTP cookies simplify the process by automatically attaching themselves to every request made to the server.
- What about these HTTP-based cookies?
Unlike client-side cookies, here a special HTTP-only cookie is used to save the session ID. The special thing about this cookie is that the client can not perform any CRUD operation upon it.
- If the client has no control over the cookies then who sets it?
Since the client has no control over this, the server itself sets the cookie using Set-Cookie an attribute in its response header.
Set-Cookie: mycookie=examplevalue; HttpOnlyThis HTTP-based cookie, unlike a client-side cookie, can not be accessed by the client even via scripts.
- Ok, how does the authentication or authorization happen using this?
- When any API call from a client is made to the server, the HTTP-only cookie is passed by default in the request header.
- The server then extracts the cookie, fetches the session ID from it and compares it with the session ID stored in its storage.
- The server validates whether the user is genuine and if they have enough permissions to perform the given actions.
- If not, a 401 or 403 response code is returned to the client indicating that the user is Unauthorised or is forbidden.
- Is there any lifetime for this session ID?
The duration for which the server stores the session details depends on the session timeout setting, which is configurable by the developer. The session timeout can happen due to two main reasons:
- Inactivity — If the user does not interact with the application for a certain period, as defined by the session timeout, the session will expire due to inactivity.
- Total session time — Even if the user is actively using the application in their session, the session will eventually expire after a certain period, which is typically set by the application. This can be considered as the total duration of the session before it needs to be renewed or the user needs to log in again.
- What happens when a timeout happens?
When times out happens, the session data is deleted from the server. This means that if a user makes an API call after the timeout on the application, the session will be closed and the user will need to log in again.
- Advantages:
- Simple and easy to implement.
- It’s easy for the server to revoke user access by invalidating the session ID.
- Disadvantage:
- In a distributed system where users may connect to different servers with each request, it gets difficult to maintain the session. For e.g. should each server keep a copy of the session data or should there be a separate auth server to handle this (Topic for next time)
- Sessions typically require server-side storage to maintain the user’s authentication state, which can significantly increase the storage and processing requirements of the server.
- Session-based token vs JWT
JWT tokens are self-contained and include all the necessary information to authenticate the user in the token itself, which means the server doesn’t have to worry about storing the information. This makes JWT tokens more scalable and easier to use with stateless mobile and web APIs.
On the other hand, session-based tokens are stored server-side, making them more secure and more flexible for applications that need to handle sensitive data. Session-based tokens also have some degree of built-in protection against session hijacking attacks, as the token remains out of reach of potential intruders.
In conclusion, both JWT and session-based tokens have their benefits and trade-offs, and the choice between them should be based on the specific needs and goals of your application.
TL;DR
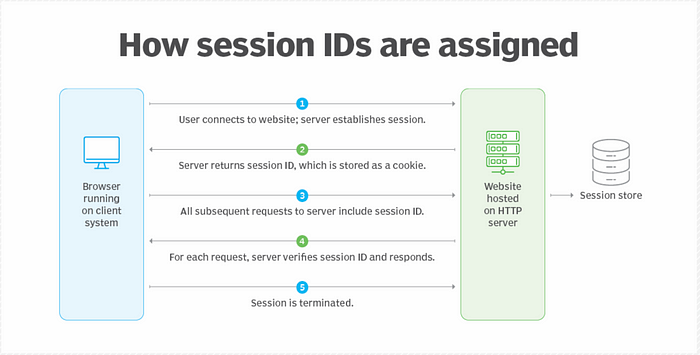
I hope you found this article useful. I would love to hear your thoughts. 😇
Thanks for reading. 😊
Cheers! 😃
If you find this article useful, you can show your appreciation by clicking on the clap button. As the saying goes, ‘When we give cheerfully and accept gratefully, everyone is blessed’.
